Подробное описание функционирования кластера высокой надежности (доступности) High-availability cluster (ha cluster). на основе публикаций Алана Робертсона (Alan Robertson) - руководителя High-Availability Linux Project в IBM Linux Technology Center.)
Используемые термины и определения
1. Под кластером (cluster) будем понимать объединение двух и более серверов в единую систему для дости-жения высокой готовности и для распределения нагрузки на сервисы. 2. Система высокой готовности (high-availability (HA) system) – отказоустойчивая компьютерная система, в которой в случае отказа гарантируются автоматическое восстановление работоспособности в течение не-скольких минут. В такой системе сервисы не принадлежат какому-то конкретному серверу в кластере, а принадлежат кластеру целиком (кластеризованные сервисы). И, в случае выхода одного сервера из строя, его сервисы быстро и автоматически начинает предоставлять другой сервер кластера. Аналогично в слу-чае отказа приложения на одном из кластерных серверов, оно будет автоматически запущено на другом сервере. 3. Failover (также fail-over) - обход отказа, обработка [ситуации] отказа (в кластерных конфигурациях). Про-цесс перевода ресурсов с неисправного сервера на резервный. 4. Failback - восстановление (откат) после отказа (в кластерных конфигурациях). 5. Уязвимое место (single point of failure, SPOF, SPF) – компонент, отказ которого приводит к отказу всей системы. Чем меньше уязвимых мест имеет система, тем выше её надёжность. Основным способом их устранения является дублирование. 6. NOD – любой сервер кластера (NOD 1, NOD, 2 etc) 7. Failsafe resources/services – находящиеся в «режиме ожидания» ресурсы и сервисы. Режим failsafe служит для быстрого запуска приложения в случае сбоя его выполнения на другом ноде (NOD). 8. MRM (Manager of Resource Monitoring) – менеджер мониторинга состояния общекластерных ресурсов и сервисов. Отслеживает функционирование сервисов нода (см. таблицу ресурсов и сервисов) и в случае сбоя в их работе извещает об этом MCS. 9. MCS (Manager of Cluster Synchronization) – специальный сервис, обеспечивающий корректное функцио-нирование общекластерных приложений и ресурсов. Непрерывно отслеживает состояние всех элементов кластерного сервера. 10. Зеркалирование файловой системы (mirroring) – это процесс, при котором изменения в файлах, сделан-ные на том ноде, где приложение или ресурс активны, автоматически пересылаются на другой нод. Зерка-лирование происходит в режиме реального времени.
Если вы системный администратор, то с вами такое уже случалось: вы как раз заказали обед, когда заверещал ваш телефон. Обед сегодня отменяется. Или другой пример: произошел отказ в работе сервера, а системный администратор исчез. Вы срываете сроки, потому что некому восстановить критически важную систему.
Кластера высокой готовности High-availability cluster (ha cluster) позволяют значительно уменьшить время простоя системы и, учитывая, что обработка отказов происходит быстро и в автоматическом режиме, системные администраторы могут закончить обедать, а пользователи свою работу. Администраторы довольны, пользователи довольны, даже менеджеры и администраторы довольны, ведь уменьшение времени простоя экономит деньги.
Поскольку высокая готовность разными людьми понимается по-разному, мы будем говорить о кластерах высокой готовности (КВГ). Кластер ВГ представляет собой набор серверов, которые совместно работают для предоставления определенных сервисов. Сервисы принадлежат не конкретному серверу, а всему кластеру. Если происходит сбой одного из серверов, его функции автоматически переходят к другому серверу кластера.
Хотя системы высокой готовности не могут полностью устранить отказы, они позволяют максимально минимизировать время простоя. И тогда этот отказ может пройти незаметно.
При правильной настройке системы высокой готовности работают как волшебники, у которых руки быстрее глаз. Действительно, корректно спроектированный, настроенный и правильно управляемый кластер добавляет девятку к доступности и уменьшает время простоя на 90%. На врезке "Магия девяток", расшифровано значение количества девяток.
Магия девяток.
Доступность сервиса обычно измеряется количеством девяток. Если сервер работает 90 процентов времени, то его доступность -- это одна девятка. Если время работы достигает 99 процентов -- доступность равна двум девяткам и т.д. Если привести эти девятки к обычному времени простоя в год, получится следующая таблица:
№ п.н.
Доступность в 9-ках
Время простоя в год
1
90.0000%
37 дней
2
99.0000%
3.7 дней
3
99.9000%
8.8 часов
4
99.9900%
53 минуты
5
99.9990%
5.3 минуты
6
99.9999%
32 секунды
Даже если вы изначально используете ненадежную операционную систему, ненадежное программное обеспечение и устанавливаете его на аппаратное обеспечение со странностями, хорошее программное обеспечение Кластера Высокой Надежности (Доступности). ощутимо улучшит ситуацию. В идеале вы сможете добиться даже трех девяток.
А если вы начнете с серьезного серверного аппаратного обеспечения, добавите к этому стабильное ядро Linux и надежное программное обеспечение, прибавьте к этому хорошо обученный персонал и отработанные процедуры поддержки, вам обеспечены лучшие результаты. В этом случае можно говорить уже о пяти девятках и более.
Реальный сервер высокой готовности
Давайте теперь разберемся как работает сервер высокой готовности. Наш пример обеспечивает четыре сервиса ВГ: NFS, Samba, DHCP и Postfix (почтовый сервер). Работает он на двух серверах, схема соединения которых приведена на рисунке 1.
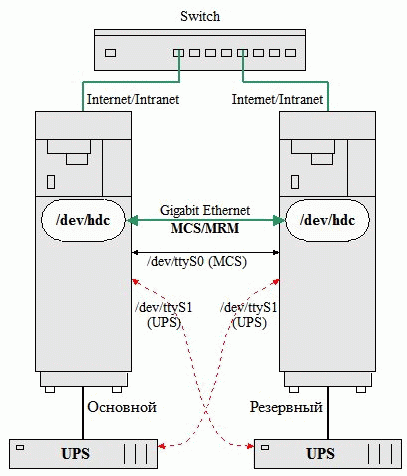
Рисунок 1.Схема физической диаграммы Кластера Высокой Надежности (доступности).
Система может использоваться как бесперебойный файл-сервер, для функционирования электронной почты, WEB,FTP-серверов, баз данных, обеспечения бесперебойного доступа в интернет и практически для всех серверных функций.
А поскольку это система ВГ, то в случае краха одного из серверов, или останова для проведения профилактических работ, просто пользователей будет продолжать обслуживать второй сервер кластера, имеющий те же данные и сервисы. Это и называется высокой доступностю.
Сервера, изображенные на рисунке 1, это системы с операционной системой Linux с несколькими IDE дисками: на одном размещен загрузочный раздел и сама система, на других -- данные и конфигурации общих сервисов.
Специальная подсистема используется для обнаружения сбоев и управления ресурсами кластера.
А другая подсистема обеспечивает постоянную синхронизацию (зеркалирование в реальном времени) раздела данных на обеих системах. Ее можно представлять как RAID1 (зеркалирование) через сеть.
Это минимальная конфигурация сервера высокой надежности с общими данными.
Выделенный канал организовывается на основе гигабитного соединения.
Надо заметить - именно из за того что используется стандартное аппаратное обеспечение, общая стоимость решения остается низкой. Насколько низкой -- это уже зависит от используемого серверного аппаратного обеспечения.
Подобные решения раньше предоставлялись только такими крупным компаниями как Sun Microsystems и так как в них используется специализированное кластерное оборудование, то стоимость таких решений высока - десятки и сотни тысяч долларов.
И именно, благодаря использованию нами новых информационных технологий, появилась возможность предложить Вашему вниманию отказоустойчивую систему высокой готовности на 75% дешевле аналогов представленных сейчас на IT рынке и обладающую той же функциональностью.
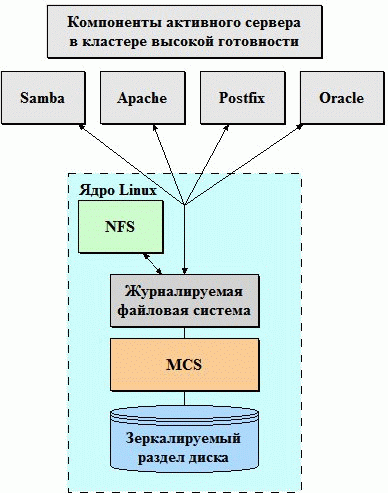
Другой способ представления системы -- это схема взаимодействия компонентов. Она проиллюстрирована на рисунке 2.
Разработка конфигурации Кластера Высокой Надежности (доступности).
Кластеры Высокой Надежности (доступности) предназначены для защиты вашей системы от сбоев. Поэтому на этапе разработки Кластера Высокой Надежности (доступности) важно искать одиночные точки отказа (single points of failure, SPOFs). Если в архитектуре системы существуют единичные элементы, отказ которых приводит к отказу всего кластера -- это одиночная точка отказа. Средство от одиночных точек отказа -- избыточность. Вообще, есть правило "трех "И" высокой готовности: избыточность, избыточность, избыточность. Если это звучит избыточно, то так оно и должно быть.
Рассмотрим системную архитектуру нашего примера. Мы видим избыточность в серверах, источниках бесперебойного питания, дисках и пр. Все это позволяет Кластеру Высокой Надежности (доступности) работать эффективно.
Рисунок 2. Cхема сервисов Кластера Высокой Надежности (доступности).
Данный пример не имеет внутренних одиночных точек отказа. Вне зависимости от того, что выйдет из строя в кластере, система продолжит функционировать. И хотя отказ репликационного канала приведет к невозможности синхронизации данных, это не вызовет отказа всего кластера, значит это не одиночная точка отказа. (В нашем примере мы рассматриваем реплицирующую систему, однако часто используются и разделяемые диски. Плюсы и минусы каждого варианта рассматриваются во врезке "Разделяемые диски и дисковая репликация"). Как можно понять из схемы, даже физическое уничтожение первичной системы не повлияет на работоспособность кластера и он продолжит функционировать.
Разделяемые диски и дисковая репликация.
Подсистема реплицирующая данные между двумя удаленными дисками любого типа через сеть реализует очень недорогое хранилище без одиночных точек отказа.
В некоторых решениях представляемых на IT рынке, в отличие от этой технологии, применяются разделяемые диски. Это обычно очень дорогие дисковые массивы RAID с несколькими подключениями, с двойными контроллеры RAID (например, IBM ServeRAID), разделяемые диски с интерфейсом fiber-channel, высокоуровневые хранилища класса IBM Enterprise Storage Server или другие EMC-решения высокого уровня. Эти системы сравнительно дороги (начиная от 50.000$ до миллионов долларов).
Но лишь в наиболее дорогих решениях нет внутренних одиночных точек отказа.
Как работает Кластер Высокой Надежности (доступности).
Программное обеспечение Кластера Высокой Надежности ( Доступности) следит за состоянием серверов в кластере, обычно используя механизм сердцебиения. Этот механизм немного напоминает своей работой процесс Linux init, но для всего кластера. Он отвечает за запуск и останов сервисов, таким образом, что каждый сервис в один момент времени выполняется где-то в кластере.
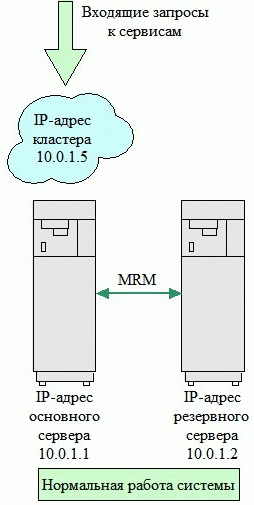
Рисунок 3. Схема обычной конфигурации HA-Кластера
Механизм сердцебиения использует скрипты аналогично стандартному init для запуска и останова сервисов. Управление ресурсами происходит на основе групп. Ресурсы одной группы всегда выполнятся на одной и той же системе в кластере. В дополнение к обычным скриптам сервисов (как nfsserver и dhcpd), механизм сердцебиения управляет IP адресами с помощью специальных скриптов. Группы ресурсов задаются в конфигурационных файлах.
Как указывалось выше, подсистема репликации удаленных дисков, обеспечивает передачу каждого записанного на первичный диск блока данных ко вторичному диску. Т.е. на ее уровне выполняется обычное зеркалирование данных с одной машины на другую в реальном времени. Первичная система задается с помощью утилиты. Устройство подсистемы репликации представляет собой ресурс, который необходимо запускать или останавливать(делать первичным или вторичным) по мере надобности.
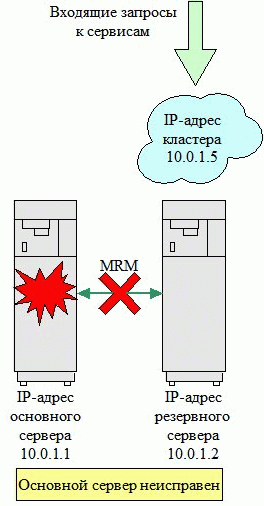
Рисунок 4. Схема сбоя в HA системе
Для кластера из двух нод, предоставляющего сервисы на одном IP адресе, необходимо три IP адреса: по одному для каждой системы в кластере для административных задач, и один для доступа ко всему кластеру. В нашем примере, кластер имеет адрес 10.10.10.20. Когда клиент обращается к сервису NFS, Samba или Postfix, он должен выполнять запрос по адресу 10.10.10.20. Механизм сердцебиения активирует этот IP адрес на той машине, где сейчас выполняется группа ресурсов.
В обычном режиме функционирования кластера, показанном на рисунке 3, система Main предоставляет сервисы и IP адрес 10.10.10.20 (Cluster) принадлежит ей. При сбое компьютера Main, система Slave перенимает IP-адрес Cluster и соответствующие сервисы. Если клиент попытается обратится к Cluster, когда Main не работает, ответит система Slave. Эта ситуация изображена на рисунке 4. Итак мы разобрались с тем, как это все работает.
Создание, настройка и тестирование систем высокой готовности -- это интересное и сложное занятие, которое мы слегка осветили в этой статье. P.S. Использованы материалы документов от Alan Robertson - руководителя проекта High-Availability Linux Project в IBM Linux Technology Center в переводе Ивана Песина. Источник: